Presentation Video
Abstract
Text-to-image diffusion models have revolutionized the way we generate personalized images from minimal reference photos. However, when misused, these tools can create misleading or harmful content, posing a significant risk to individuals. Current methods attempt to mitigate this by subtly altering user images to make them ineffective for unauthorized use. However, these poisoning-based defenses often fall short due to reliance on simplistic heuristics and a lack of resilience against basic image transformations like Gaussian filtering.
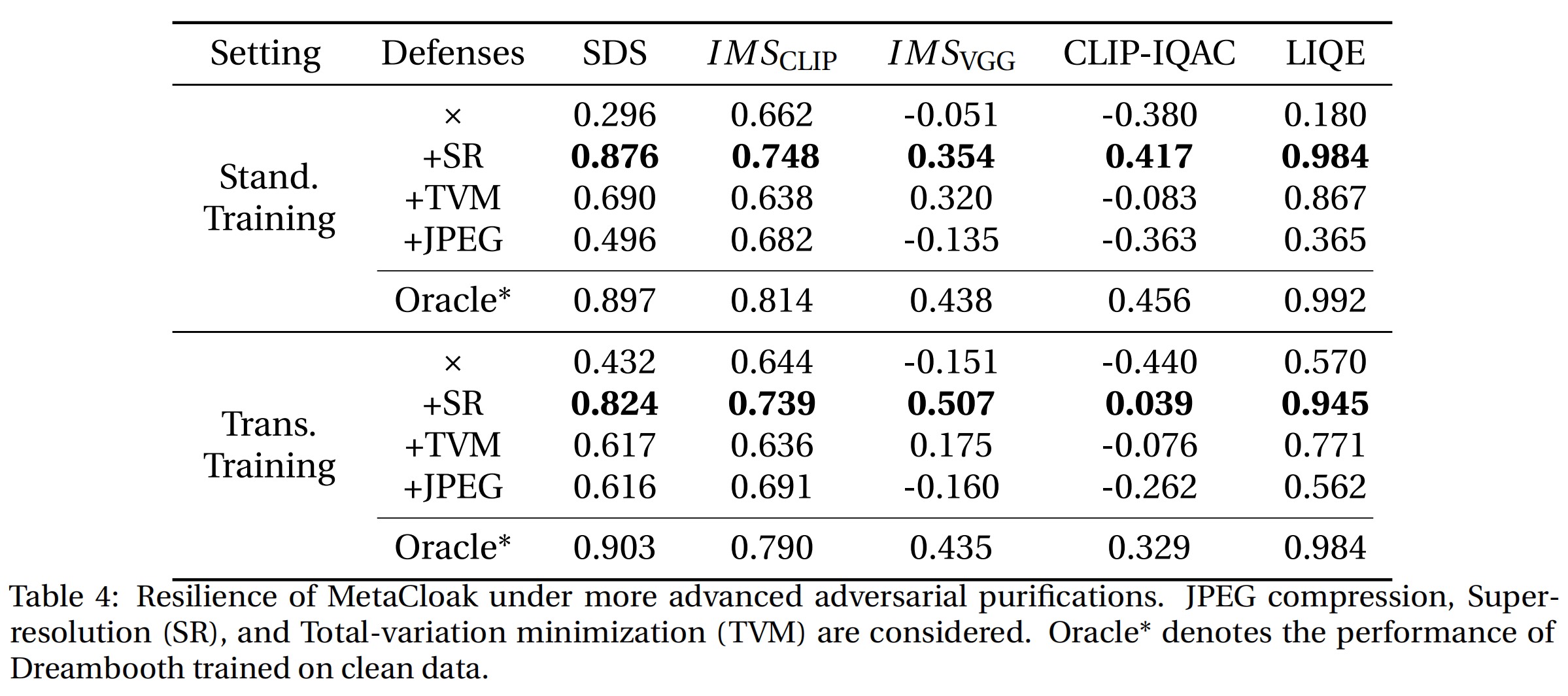
To combat these shortcomings, we introduce MetaCloak, an innovative approach that leverages a meta-learning framework to tackle the bi-level poisoning challenge. MetaCloak not only addresses the limitations of previous methods by incorporating a transformation sampling process for crafting robust and transferable perturbations but also utilizes a pool of surrogate diffusion models to ensure these perturbations are model-agnostic. An additional layer of innovation is applied in the form of a denoising-error maximization loss, designed to induce semantic distortion resilient to transformations, thus enhancing the generation's personalized touch.
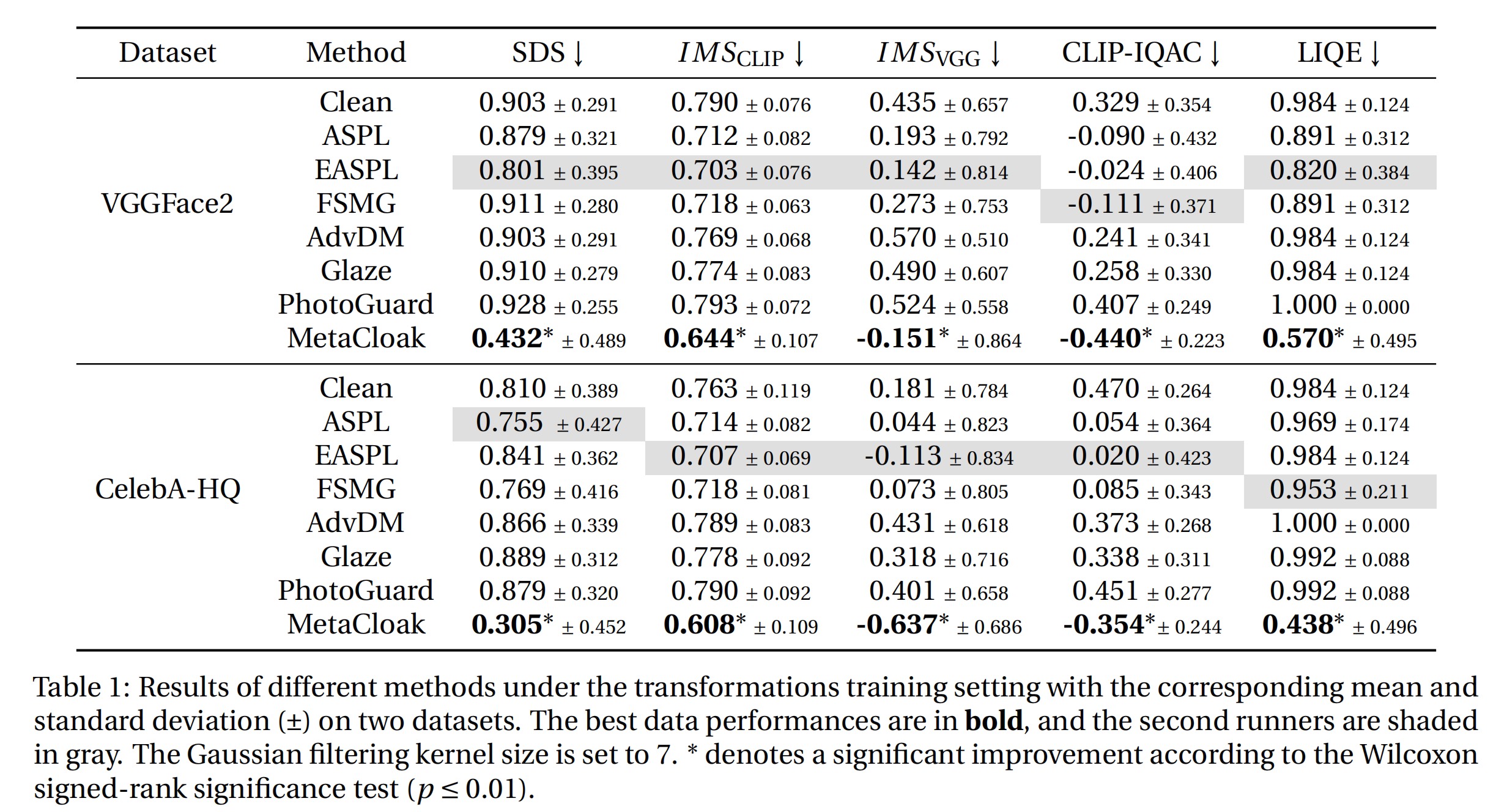
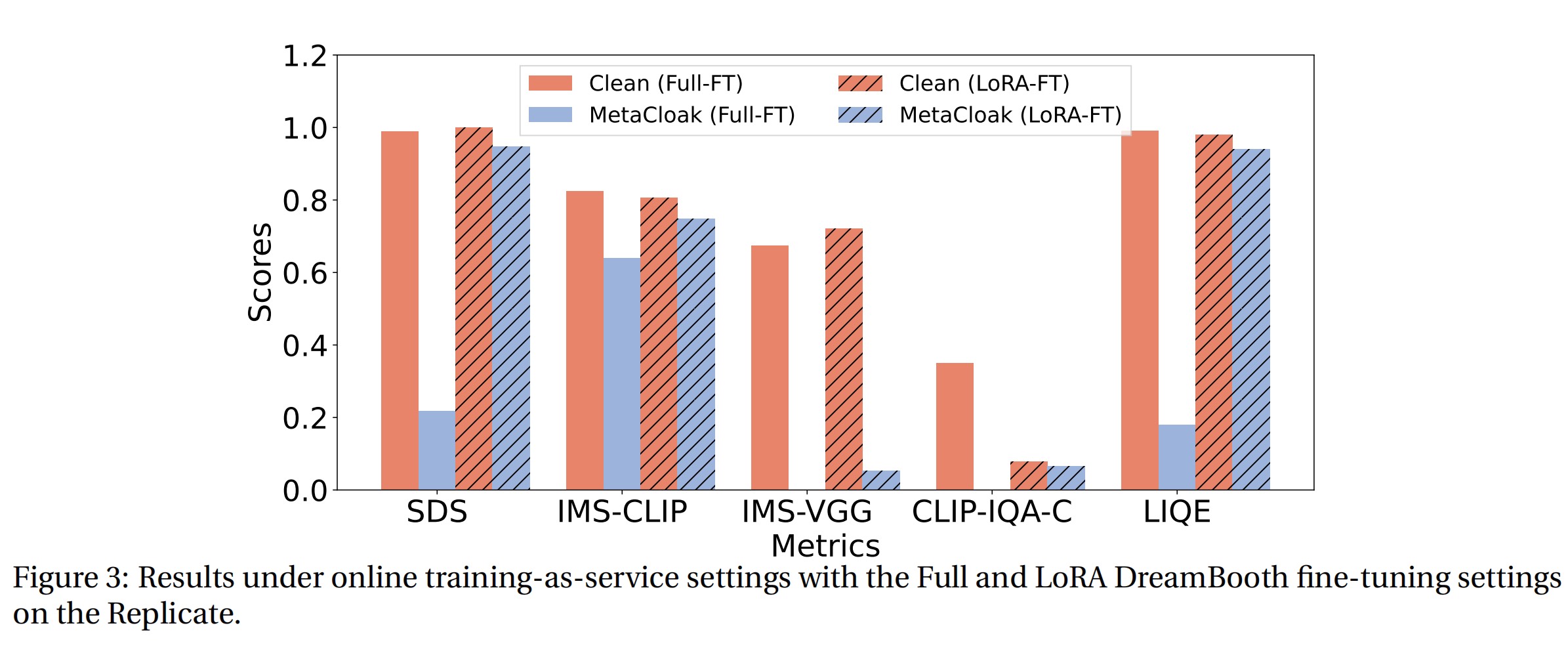
Our comprehensive tests across the VGGFace2 and CelebA-HQ datasets demonstrate MetaCloak's superior performance over existing solutions. Remarkably, MetaCloak can deceive online training platforms like Replicate in a black-box fashion, showcasing its practical effectiveness in real-world applications. For those interested in further exploration or application, our code is publicly available at https://github.com/liuyixin-louis/MetaCloak.
Overall Algorithm
The algorithm of MetaCloak is shown as follows: